Elasticsearch: Nền tảng Tìm kiếm và Phân tích Dữ liệu
Giới thiệu
Elasticsearch là một công cụ mã nguồn mở, được thiết kế với mục tiêu giúp tổ chức và quản lý dữ liệu một cách hiệu quả. Phát triển lần đầu tiên vào năm 2010 bởi Shay Banon, Elasticsearch nhanh chóng trở thành một phần không thể thiếu trong lĩnh vực tìm kiếm và phân tích dữ liệu, đặc biệt trong bối cảnh dữ liệu phi cấu trúc đang bùng nổ. Đây là một phần của Elastic Stack (ELK Stack), bao gồm Logstash và Kibana, cung cấp một giải pháp mạnh mẽ để thu thập, lưu trữ và phân tích dữ liệu.
Bài viết này sẽ cung cấp cái nhìn tổng quan về Elasticsearch, từ các khái niệm cốt lõi cho đến các kỹ thuật nâng cao và ứng dụng thực tế. Sự hiểu biết về Elasticsearch không chỉ giúp nhà phát triển tạo ra các ứng dụng tìm kiếm hiệu quả, mà còn có thể cải thiện hiệu suất truy vấn dữ liệu trong các hệ thống lớn.
Kiến thức nền tảng
Các khái niệm cốt lõi và nguyên lý hoạt động
Elasticsearch sử dụng khái niệm lân cận để lưu trữ và tìm kiếm dữ liệu. Dữ liệu được lưu trữ trong các index (chỉ mục), và mỗi chỉ mục chứa một hoặc nhiều document (tài liệu). Sharding và replication là hai khái niệm quan trọng, trong đó sharding cho phép chia nhỏ dữ liệu lớn ra thành các phần nhỏ hơn để dễ quản lý và truy vấn, còn replication giúp tăng tính sẵn sàng của dữ liệu.
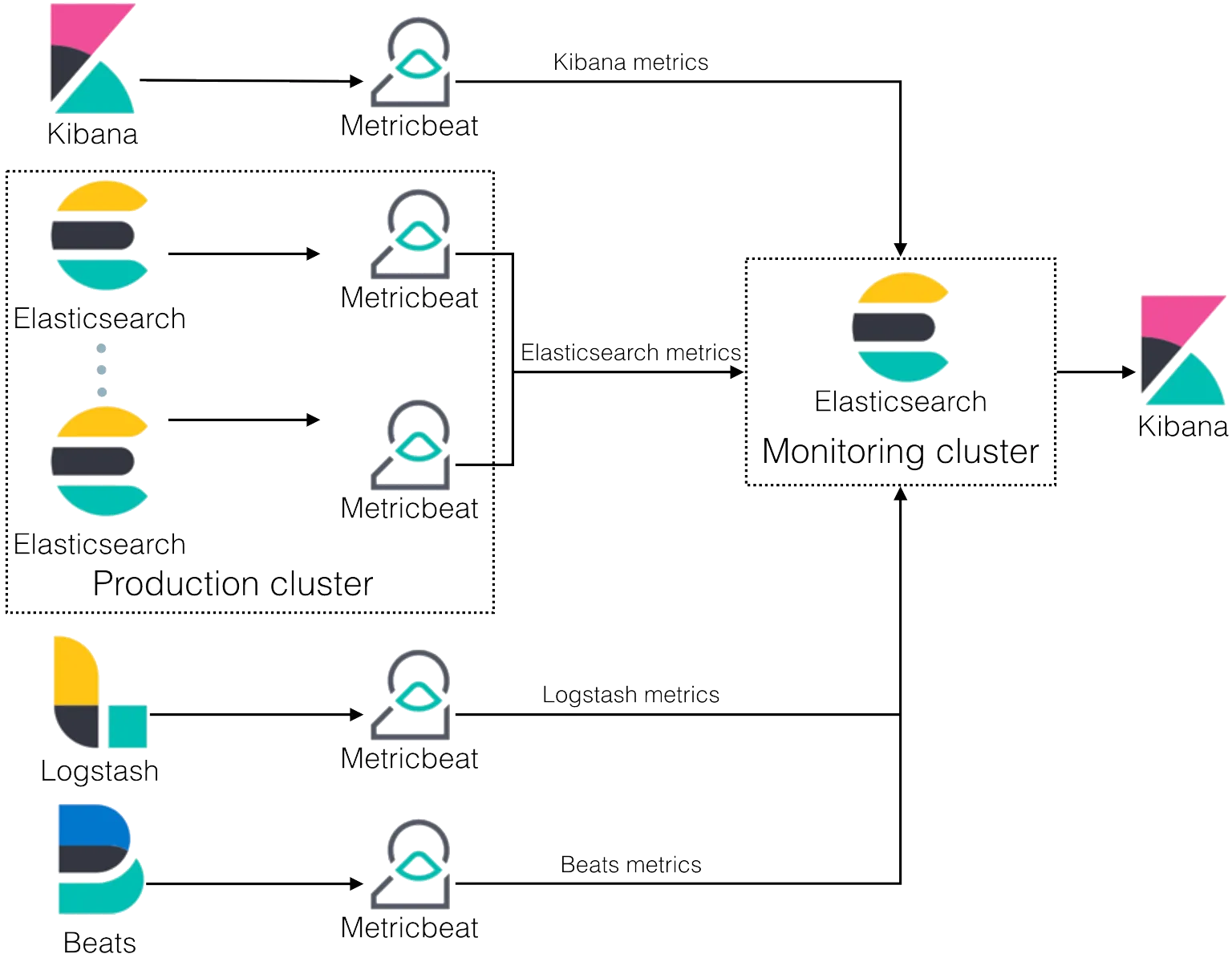
Kiến trúc và mô hình thiết kế phổ biến
Mô hình kiến trúc của Elasticsearch dựa trên các node (nút) kết nối với nhau để tạo thành cluster (cụm). Mỗi node trong cluster có thể chứa một hoặc nhiều index và cung cấp khả năng tìm kiếm, lưu trữ dữ liệu và quản lý.
So sánh với các công nghệ/kỹ thuật tương tự
Khi so sánh Elasticsearch với các công nghệ như Apache Solr, có thể thấy rằng Elasticsearch cung cấp tính năng phân tán tuyệt vời và khả năng tự động hóa cao hơn. Solr, trong khi mạnh mẽ trong một số lĩnh vực, thường cần nhiều cấu hình hơn và không linh hoạt như Elasticsearch trong việc xử lý dữ liệu phi cấu trúc.
Các kỹ thuật nâng cao
1. Tìm kiếm Fuzzy
Tìm kiếm fuzzy cho phép tìm kiếm các từ gần giống nhau, giúp cải thiện khả năng tìm kiếm khi người dùng không nhập đúng chính xác từ khóa.
json GET /my_index/_search { "query": { "fuzzy": { "user": { "value": "karl", "fuzziness": "AUTO" } } } } Trong đoạn mã trên, truy vấn fuzzy sẽ tìm kiếm các tài liệu có trường user gần giống với karl, với độ mờ tự động.
2. Tìm kiếm với Bộ lọc (Filters)
Sử dụng bộ lọc để cải thiện hiệu suất tìm kiếm mà không cần tính toán độ liên quan (relevance).
json GET /my_index/_search { "query": { "bool": { "must": { "match": { "title": "Elasticsearch" } }, "filter": { "range": { "publish_date": { "gte": "2021-01-01", "lte": "2023-01-01" } } } } } } Truy vấn trên sẽ tìm kiếm tất cả các tài liệu có tiêu đề "Elasticsearch" và nằm trong khoảng ngày đăng bài từ 1/1/2021 đến 1/1/2023.
3. Chỉ mục theo thời gian (Time-series Indexing)
Elasticsearch hỗ trợ chỉ mục thời gian, cho phép lưu trữ dữ liệu theo khoảng thời gian với các chiến lược tái chế.
json PUT /logs-2023.01.01 { "settings": { "number_of_shards": 1, "number_of_replicas": 1 } } Đoạn mã trên tạo một chỉ mục mới cho ngày 1 tháng 1 năm 2023 với một shard và một replica.
4. Tự động hoàn thành (Autocomplete)
Elasticsearch có hỗ trợ cho tính năng tự động hoàn thành, giúp cải thiện trải nghiệm người dùng.
json GET /my_index/_search { "suggest": { "song-suggest": { "prefix": "son", "completion": { "field": "suggest" } } } } Dùng truy vấn trên, Elasticsearch sẽ đưa ra gợi ý cho các từ bắt đầu bằng "son".
Tối ưu hóa và Thực tiễn tốt nhất
Các chiến lược tối ưu hóa hiệu suất
- Sharding hợp lý: Số lượng shard cần được thiết lập hợp lý để tránh tình trạng quá tải.
- Sử dụng replica: Tăng số lượng replica để cải thiện tính khả dụng và tốc độ truy vấn. 3. Sử dụng cache: Tối ưu hóa bộ nhớ đệm để giảm bớt tải cho cụm.
Các mẫu thiết kế và kiến trúc được khuyến nghị
Sử dụng kiến trúc microservices để phân tán lưu trữ và truy vấn giúp giảm thiểu thời gian phản hồi.
Xử lý các vấn đề phổ biến và cách khắc phục
- Tình trạng đầy bộ nhớ: Giảm số lượng shard hoặc tăng kích thước node.
- Truy vấn chậm: Tối ưu hóa truy vấn bằng cách sử dụng filter hoặc cache.
Ứng dụng thực tế
Ví dụ ứng dụng: Xây dựng Công cụ Tìm kiếm Blog
Bước 1: Tạo chỉ mục để lưu trữ bài viết blog.
json PUT /blog { "mappings": { "properties": { "title": { "type": "text" }, "content": { "type": "text" }, "publish_date": { "type": "date" }, "author": { "type": "keyword" } } } } Chỉ mục blog sẽ lưu trữ các bài viết với các thuộc tính tiêu đề, nội dung, ngày xuất bản, tác giả.
Bước 2: Chèn dữ liệu vào chỉ mục.
json POST /blog/_doc { "title": "Giới thiệu về Elasticsearch", "content": "Elasticsearch là một công cụ mạnh mẽ...", "publish_date": "2023-01-15", "author": "Nguyễn Văn A" }
Bước 3: Tìm kiếm
json GET /blog/_search { "query": { "match": { "content": "công cụ mạnh mẽ" } } } Kết quả tìm kiếm sẽ trả lại tất cả bài viết chứa cụm từ "công cụ mạnh mẽ".
Kết quả và phân tích hiệu suất
Khi sử dụng Elasticsearch cho tìm kiếm blog, có thể nhận thấy độ chính xác và tốc độ của các truy vấn được cải thiện đáng kể. Trên dữ liệu lớn, tính năng tìm kiếm nhanh và khả năng mở rộng linh hoạt là những yếu tố then chốt.
Xu hướng và Tương lai
Các xu hướng mới nhất
- Khai thác trí tuệ nhân tạo (AI): Tích hợp AI có thể giúp cải thiện quá trình phân tích và tìm kiếm.
- Tìm kiếm tự nhiên: Xu hướng phát triển giao diện tìm kiếm gần gũi hơn với người dùng.
Các công nghệ/kỹ thuật đang nổi lên
Cùng với sự phát triển của machine learning và deep learning, Elasticsearch đang dần áp dụng các kỹ thuật học máy vào quy trình tìm kiếm và phân tích dữ liệu.
Dự đoán về hướng phát triển trong tương lai
Với sự gia tăng lượng dữ liệu và nhu cầu tìm kiếm thông tin theo cách hiệu quả hơn, chúng ta có thể hình dung rằng Elasticsearch sẽ tiếp tục mở rộng và phát triển, tương thích với nhu cầu mới trong không gian dữ liệu.
Kết luận
Elasticsearch là một công cụ mạnh mẽ trong quản lý và tìm kiếm dữ liệu. Với những kỹ thuật nâng cao và phương pháp tối ưu hóa, nhà phát triển có thể xây dựng các ứng dụng tìm kiếm hiệu quả. Hãy tìm hiểu thêm thông qua các tài nguyên học tập bổ sung như tài liệu chính thức của Elasticsearch hay tham gia vào các diễn đàn và cộng đồng công nghệ.
Tài nguyên học tập bổ sung
- Elasticsearch Official Documentation
- Elasticsearch: The Definitive Guide
- Coursera: Full-Stack Data Science
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn sâu sắc và chi tiết về Elasticsearch, cùng với các kỹ thuật và xu hướng quan trọng trong lĩnh vực này.
Câu hỏi thường gặp
1. Làm thế nào để bắt đầu với chủ đề này?
Để bắt đầu, bạn nên tìm hiểu các khái niệm cơ bản và thực hành với các ví dụ đơn giản.
2. Nên học tài liệu nào để tìm hiểu thêm?
Có nhiều tài liệu tốt về chủ đề này, bao gồm sách, khóa học trực tuyến và tài liệu từ các nhà phát triển chính thức.
3. Làm sao để áp dụng chủ đề này vào công việc thực tế?
Bạn có thể áp dụng bằng cách bắt đầu với các dự án nhỏ, sau đó mở rộng kiến thức và kỹ năng của mình thông qua thực hành.